Other architecture & PoCs그 외 아키텍처 & PoC
Logo Segmentation Experiment Workbench
A /test-centered workbench that separates warp correction, anchor generation, Grounding DINO + SAM segmentation, and post-processing so each failure can be inspected. The route was earned: four SAM-prompt strategies and a vision-LLM coordinate approach failed before OCR + contour + rough vision ROI became the practical hybrid. This is not a production-validated automatic extractor; its sharpness/noise metrics compare settings, not absolute visual quality, and cleanup cannot recover foreground that segmentation missed. Troubleshooting archive →warp 보정, anchor 생성, Grounding DINO + SAM segmentation, 후처리를 분리해 실패를 각각 관찰하는 /test 중심 워크벤치입니다. 이 경로는 설계된 게 아니라 얻어낸 것입니다: SAM prompt 전략 4개와 vision LLM 좌표 접근이 실패한 뒤 OCR + contour + 대략적 vision ROI가 현실적인 hybrid가 됐습니다. 이는 프로덕션 검증을 마친 자동 추출기가 아닙니다. sharpness/noise 지표는 설정 비교용이지 절대적 시각 품질 판정이 아니며, 후처리는 segmentation이 놓친 전경을 복구하지 못합니다. 트러블슈팅 아카이브 →
Experiments & honest failures실험과 정직한 실패
I value the decision to stop as much as the decision to ship.출시 결정만큼이나 멈추는 결정도 중요하게 봅니다.
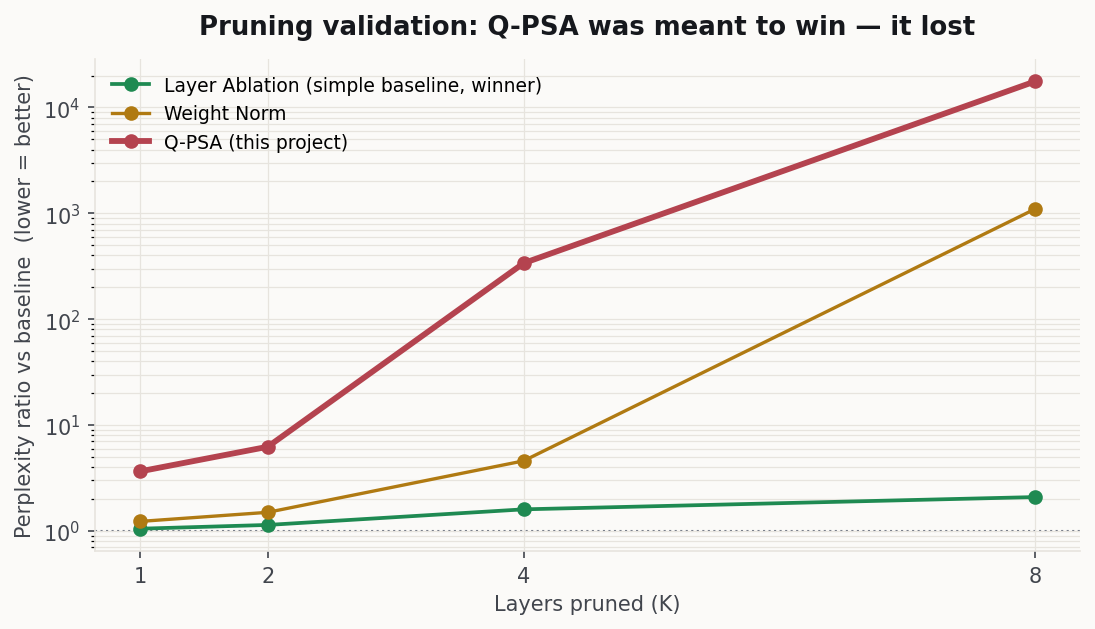
Q-PSA (red) vs a simple baseline — perplexity explodes as more layers are pruned. Lower is better; the gap is why I killed it.Q-PSA(빨강) vs 단순 베이스라인 — 레이어를 더 제거할수록 perplexity가 폭발. 낮을수록 좋으며, 이 격차가 프로젝트를 종료한 이유입니다.
Q-PSA
Discrete perturbation to estimate layer importance in quantized LLMs.양자화 LLM의 레이어 중요도를 discrete perturbation으로 추정.
Decision: Killed at Phase 1 — pruning the bottom-ranked layer raised PPL 3.65× with Q-PSA versus 1.05× with Layer Ablation, while scoring took 155 minutes vs 7 seconds (~1,300× slower).Phase 1에서 종료 — 가장 덜 중요하다고 본 레이어 하나를 제거했을 때 Q-PSA는 PPL이 3.65배, Layer Ablation은 1.05배였고, 점수 산출은 155분 vs 7초(약 1,300배)였습니다.
Why it failed: perturbation sensitivity ≠ layer importance, and a gradient-free GGUF platform blocked the structural experiments needed to rescue the hypothesis. What survived was more useful than the method: Layer Ablation as a fast importance metric, a reusable in-memory GGUF perturbation pipeline, and explicit kill criteria. Full results →실패 이유: perturbation 민감도 ≠ 레이어 중요도, 그리고 gradient-free GGUF 플랫폼이 가설을 살리기 위한 구조 실험을 막았습니다. 방법론보다 더 쓸모 있게 남은 것은 빠른 중요도 지표인 Layer Ablation, 재사용 가능한 in-memory GGUF perturbation 파이프라인, 명시적 kill criteria였습니다. 전체 결과 →

The ray variant finds a full 163-step path where plain WFC stalls. It demonstrates recovery on this maze, not a general connectivity guarantee.ray 변형이 plain WFC가 막히는 이 미로에서 163-step 경로를 찾아냅니다. 이 사례의 복구 결과이지, 일반적인 연결성 보장은 아닙니다.
Circle-WFC
Replacing A* pathfinding with geometry-guided Wave Function Collapse.A* 경로탐색을 geometry-guided WFC로 대체 시도.
Insight: Found the structural mismatch between local consistency and global connectivity; stopped treating it as a standalone pathfinder.local consistency와 global connectivity의 구조적 불일치를 확인하고, 단독 pathfinder로 보는 것을 중단.
The honest pivot is still a research direction, not a validated reducer: Circle-WFC could propose corridors, anchors, or road zones, while A* or JPS (jump point search) computes the final path and owns complex topology. Full result →정직한 피벗은 아직 검증된 reducer가 아니라 후속 연구 방향입니다. Circle-WFC가 corridor·anchor·road zone 후보를 만들고, A*나 JPS(jump point search)가 최종 경로와 복잡한 topology를 맡는 구조입니다. 전체 결과 →
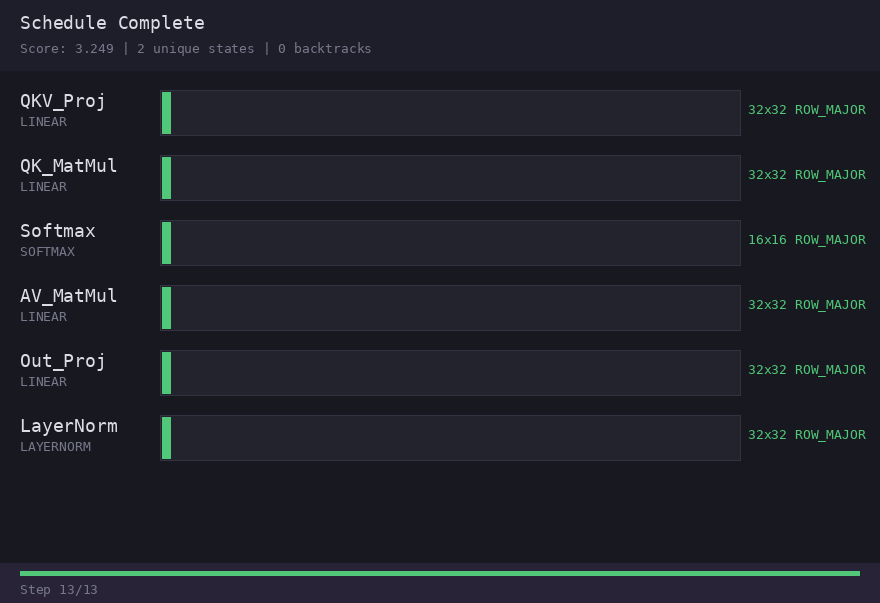
Final attention-block schedule — on the synthetic 12KB-SRAM benchmark, WFC matches exact dynamic programming. Search correctness on this case is validated; production advantage is not.어텐션 블록의 최종 스케줄 — 가상 12KB-SRAM 벤치마크에서 WFC가 exact dynamic programming과 일치합니다. 이 사례의 탐색 정확성은 확인됐지만, 프로덕션 우위는 아닙니다.
HW-WFC v2.9
Constraint-driven AI compiler scheduling R&D.제약 기반 AI 컴파일러 스케줄링 R&D.
Result: Matched Exact DP's optimum on the benchmark — but Exact DP already solves it in ~7–10ms, so the WFC speed difference has no practical value.벤치마크에서 Exact DP 최적값과 일치 — 하지만 Exact DP도 이미 약 7–10ms에 풀어 WFC의 속도 차이는 실질적 가치가 없습니다.
The useful boundary was the cost model: its average correlation with measured GPU timing was only Spearman ρ=+0.52 — directional, not reliable enough for production scheduling. The differentiating 12KB SRAM spec exists on no real GPU; with A100/H100-scale SRAM the benchmark becomes trivial. Better calibration would require diverse hardware profiling data beyond this software-only experiment. Full result →유의미한 경계는 cost model이었습니다. 실제 GPU timing과의 평균 상관은 Spearman ρ=+0.52로, 방향성은 있지만 프로덕션 스케줄링 판단에는 부족했습니다. 차별화를 만든 12KB SRAM 스펙은 실제 GPU에 없고, A100/H100 규모 SRAM에선 문제가 trivial해집니다. 더 나은 교정에는 이 소프트웨어 실험 범위를 넘는 다양한 하드웨어 profiling 데이터가 필요합니다. 전체 결과 →